原文:Hybrid Particle Filter–Particle Swarm Optimization Algorithm and Application to Fuzzy Controlled Servo Systems | IEEE Journals & Magazine | IEEE Xplore
智能优化算法课程的汇报要求,找了一篇PSO算法相关的看看,Intro部分也写得挺详细,对元启发式算法(进化)有个概述。慢慢写着,之前课上代课的老师讲了他做的大规模优化问题也有点意思,也许之后会写一下。
简介
元启发式算法
元启发式算法(metaheuristic algorithm),也称自然启发算法(nature-inspired algorithms)或进化算法(evolutionary algorithms, EAs)。
这里的”进化“指的是将类似于生物进化的一些过程如繁殖、突变、重组和选择等概念用到优化问题中。进化算法的一个优势在于它有能力跳出局部最优而寻找全局最优,但进化算法在特定类的问题上也不能保证给出全局最优。
主要工作
如作者总结,文章的主要工作有二:
- 提出了一种新的混合元启发式算法(hybrid metaheuristic algorithm)粒子过滤-群算法(PF-PSO)
- 在用于伺服系统的位置控制的比例积分的模糊控制器的最优调谐中应用PF-PSO算法
PF-PSO算法
PF – PSO背后的思想结合了两个算法:用于移动机器人定位的粒子滤波算法(PF)和粒子群优化算法(PSO)。
这种合并用随机生成的粒子种群取代了群体运动学的定义
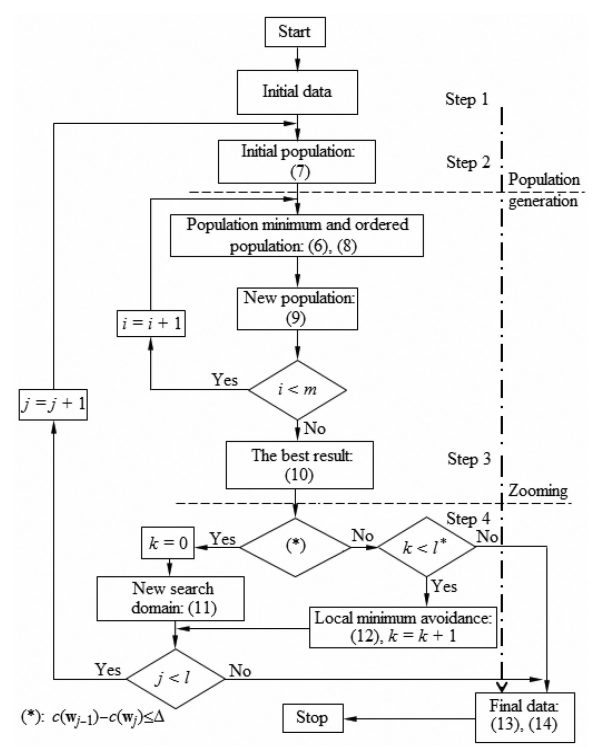
算法的流程图如下:
基本定义
优化问题就是要找到在一个搜索域 D⊂Rds( ds 为搜索域的维度)中最小化(或最大化)代价函数 的最优点 c:D→Rds,即
x∗=argx∈Dminc(x)
一个第 k 代 n 维(包含 个粒子/元素)的粒子群 定义为如下离散集合:
Pk={x1,x2,...,xn}
粒子群的表现 由每个元素的代价函数计算得到:
pf(Pk)={y1,y2,...,yn}={c(x1),c(x2),...,c(xn)}
粒子群最小就是该粒子群 中使得代价函数最小的粒子 xk∗ .
一个第 k 代的有序粒子群 P~k 定义为粒子群中粒子按代价函数值大小从小到大的顺序排序的集合:
P~k={x~1,x~2,...,x~n}
其中 c(x~1)≤c(x~2)≤...≤c(x~n).
Step 1 初始化算法参数
- c:代价函数(cost function)
- D:搜索域(search domain)
- n:粒子群维度(population dimension or the number of particles also called agents)
- m:每次缩放需要经过的粒子群代数/最大迭代次数(the number of populations generated for each zooming and also the maximum number of iterations)
- SN>0:从有序粒子群中采样的方差(the variance of normal distribution in random selection (sampling))
- SZ,1>0:正态噪声的初始方差(the initial variance of normal distribution in noise definition)
- ρ1>0:初始邻域半径(the initial vicinity radius)
- αρ>1:邻域半径的缩放因子(the zooming factor for vicinity radius)
- αz>1:正态噪声的缩放因子(the zooming factor for normal distribution in noise definition)
- l:缩放的次数(the number of zooms)
- l∗:跳出局部最优的最大尝试次数(the maximum number of local minimum avoiding trials)
- Δ>0:两次连续的缩放直接的表现差异(the relative performance between two consecutive zooms)
Step 2 迭代产生粒子群
根据参数,进行 i=1,2,...,m 次迭代生成,i=1 即第一代从搜索域的均匀分布中产生:
P1=unirand(D1,n)
每代生成计算粒子群的表现,存储最好的结果:
U={xk∗∣xk∗=argxi∈Pkminc(xi),k=1,...,m}
同时得到有序粒子群 P~k .
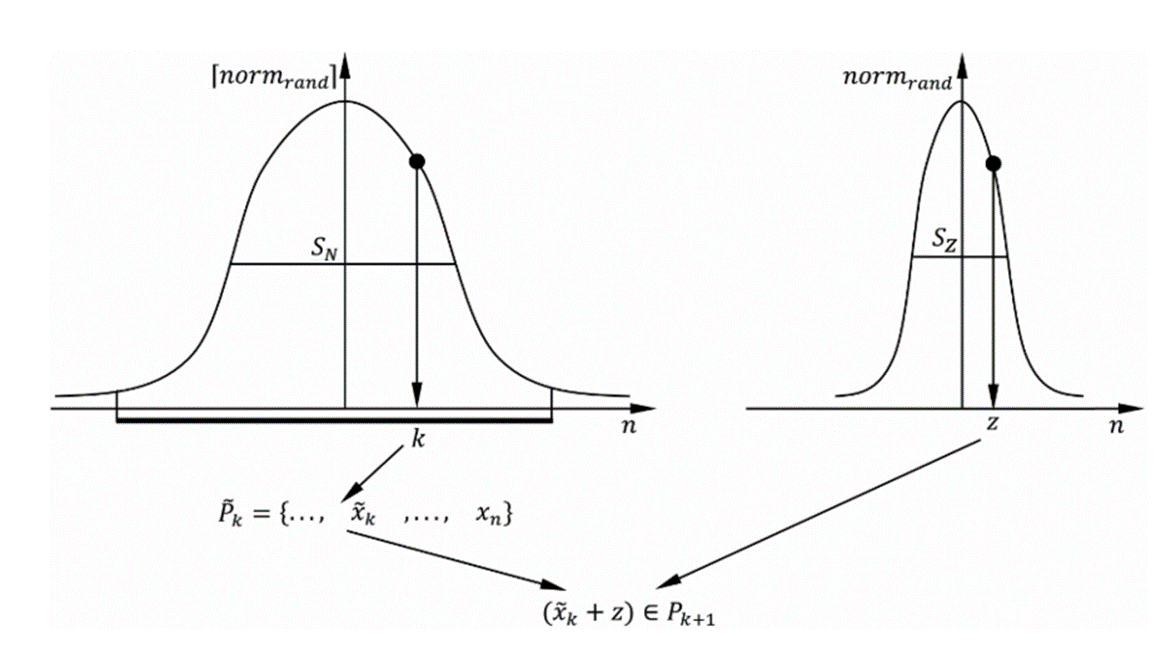
i≥2,即第二代之后新的粒子群通过如下的采样得到:
Pk={xi∣xi=x⌈normrand(0,SN)⌉+normrand(0,SZ,j)x[normrand(0,SN)∈Pk−1,i=1,...,m}
其中,⌈normrand(0,SN)⌉ 表示以0为均值,SN 为方差的正态随机方式采样有序粒子群中的元素索引,所以离粒子群最优更近的元素更容易被保留。normrand(0,SZ,j) 是一个用于产生新的粒子的正态分布。
Step 3 存储最优结果
在第二步中经过 m 次迭代我们得到了一个每代的最优结果集合 U,在进行搜索域缩放之前我们要存储这个集合中的最优值,算法总共需要进行 l 次搜索域缩放,所以我们需要存储 l 次,即:
W={wj∣wj=argxi∈Uminc(xi),j=1,...,l}
根据两代之间代价函数最优值的差异,就可以在缩放的时候决定是进一步减小搜索域还是扩大搜索域以跳出局部最优。
Step 4 缩放搜索范围
根据参数,进行 j=1,2,...,l 次搜索域缩放,每次缩放完成后回到 Step 2 重新生成粒子群迭代。
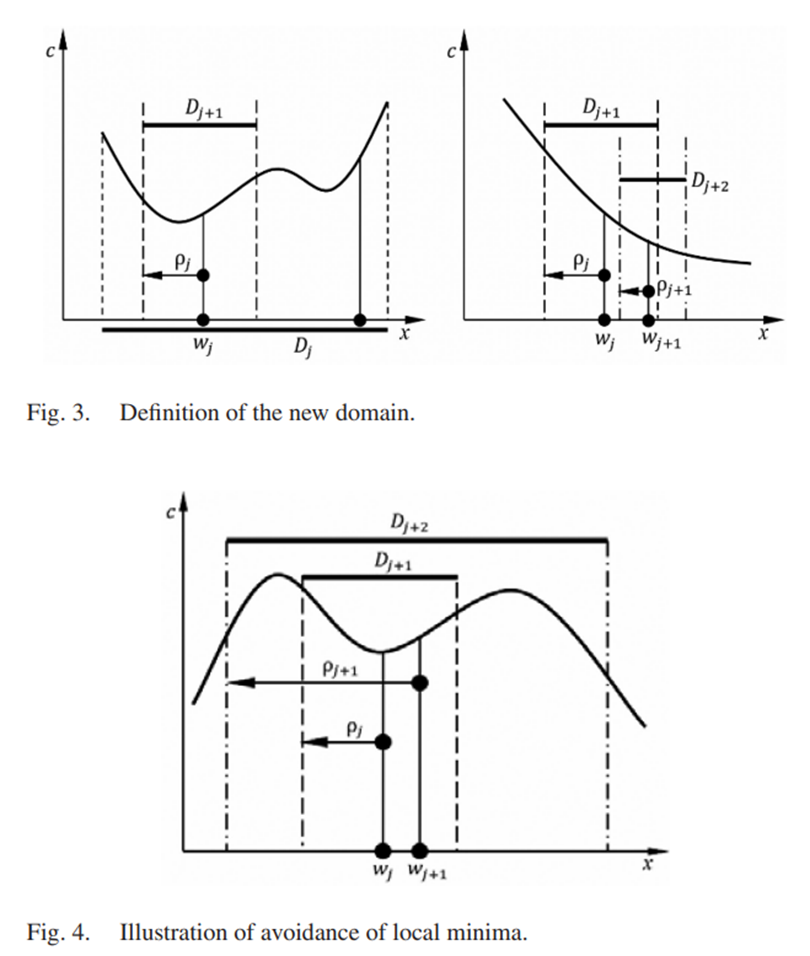
如果 c(wj−1)−c(wj)≤Δ,k<l,新的搜索域变为:
Dj+1=V(wj,ρj)∩D
其中 V(wj,ρj) 是以 wj 为中心半径为 ρj 的邻域。同时 k 重置为0。
这个邻域和由于下一轮粒子群生成的随机分布的方差由下面的公式缩小:
ρj+1=αρρj,SZ,j+1=αZSZ,j
如果 c(wj−1)−c(wj)>Δ,k<l,k<l∗,新的搜索域同样变为:
Dj+1=V(wj,ρj)∩D
同时 k=k+1 .
邻域和用于下一轮粒子群生成的随机分布的方差由下面的公式放大:
ρj+1=αρρj,SZ,j+1=αZSZ,j
终止条件
-
经过 l 次搜索域缩放,即进行了 l×m 轮粒子迭代生成。
-
如果次连续的缩放直接的表现差异 c(wj−1)−c(wj)≤Δ 的同时已经进行了 l∗ 次避免局部最小(扩大搜索域)的操作。
满足以上条件中的一个算法就会终止,输出得到的最优点和最优代价函数:
x∗=ωj,c(x∗)=c(ωj)
