
原文:Molecular Contrastive Learning of Representations via Graph Neural Networks
老板让我学习一下这篇写作思路,遂看。
文章上来就是甩了5页MolCLR的结果然后方法部分简单介绍原理,之后接着参考文献,最后是7页的补充材料介绍细节。
简介
分子表示是制备新型、有效的化合物的基础和关键,分子机器学习在分子性质预测和药物发现方面具有广阔的应用前景。
分子表示此前传统的标准方法有如ECFP,随着机器学习方法发展,数据驱动的分子表示学习也逐渐应用于化学性质预测、化学建模和分子设计等方面。
可能的稳定的化合物空间非常庞大,找到一种包含足够信息量从而能够在整个可能的化合物空间上泛化的分子表示方法是具有挑战性的,具体体现在:
- 难以完整地表示分子的多重信息(比如基于字符串的表示方法SMILES就难以编码分子结构的拓扑信息)
- 化合物空间非常庞大
- 分子学习相关benchmark中的标签数量远远不足
对比学习的一般流程
- 数据增强
- 构建正负例(通常采用个体判别这一代理任务)
- 特征编码(特征抽取)
- 在特征上根据对比损失训练网络
主要工作
本文主要给出了一种用图神经网络对分子图进行特征编码后进行对比学习进而实现分子表示的模型(MolCLR)。
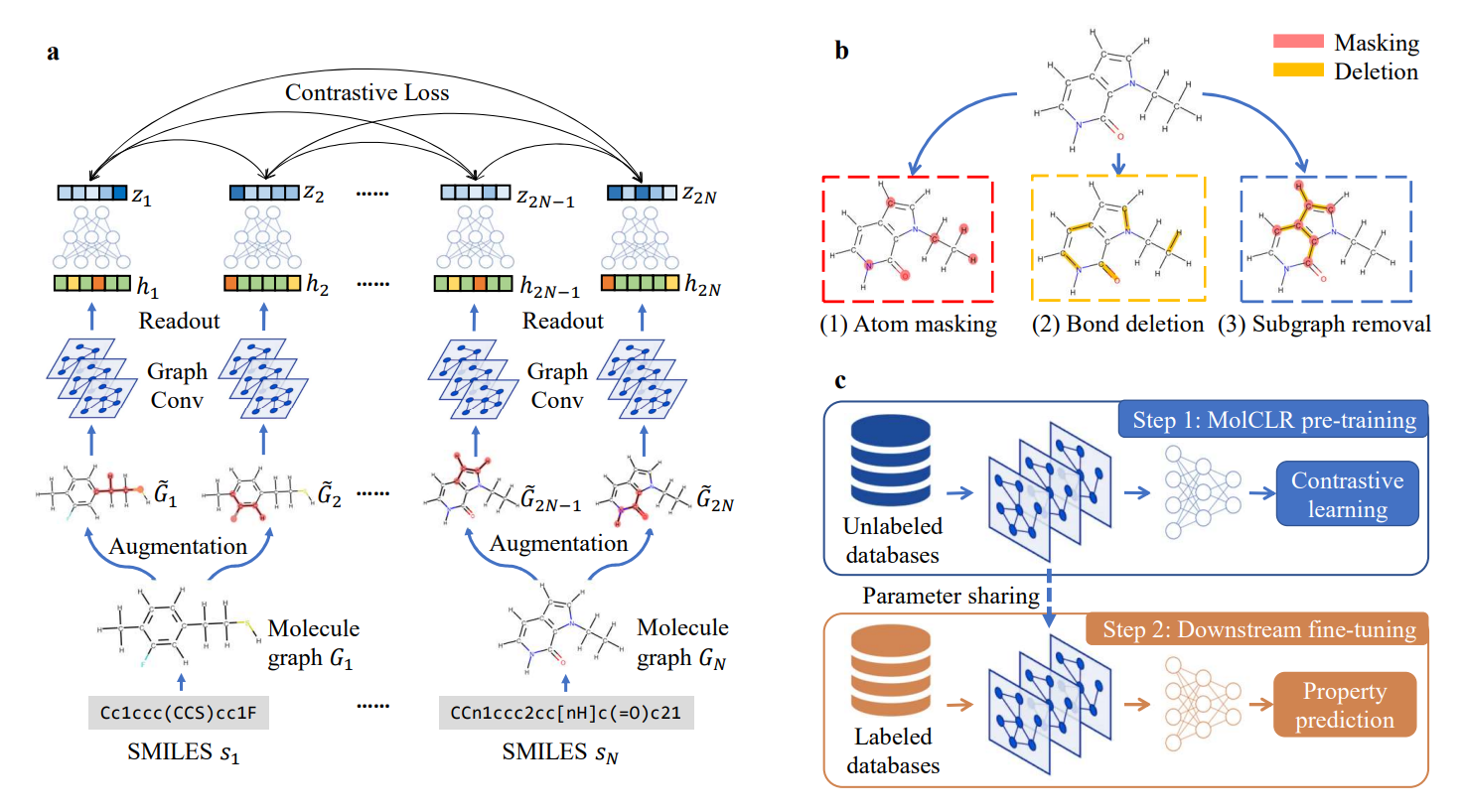
MolCLR首先通过对SMILE数据集构建对应的分子图,然后使用三种增强方法:原子掩膜、化学键删除和子图删除进行数据增强,接着根据对比学习的一般流程用GNN做一个特征抽取,这里再通过了一个MLP进行非线性投射,将通过GNN的表示进一步映射为潜在向量,最后将一分子图和其增广出来的分子图构成的潜在向量数据对都看做正例,而这一分子图和其他分子图以及他们的增广分子图的潜在向量数据对都视作负例进行对比学习,计算对比损失NT-Xent。
具体训练过程分为预训练和下游任务的微调,两个阶段GNN的参数是共享的,而MLP的参数则需要随机初始化根据下游任务训练,我理解即根据不同任务调整预测头,而用于表示的GNN骨干网络是通过对比学习在大量无标签数据上习得的。