
原文:Mixup for Node and Graph Classification | Proceedings of the Web Conference 2021 (acm.org)
简介
Mixup 是一种数据增强方法,用于训练基于神经网络的图像分类器,它对一对图像的特征和标签进行插值以生成合成样本。本文主要将该方法扩展到图数据。
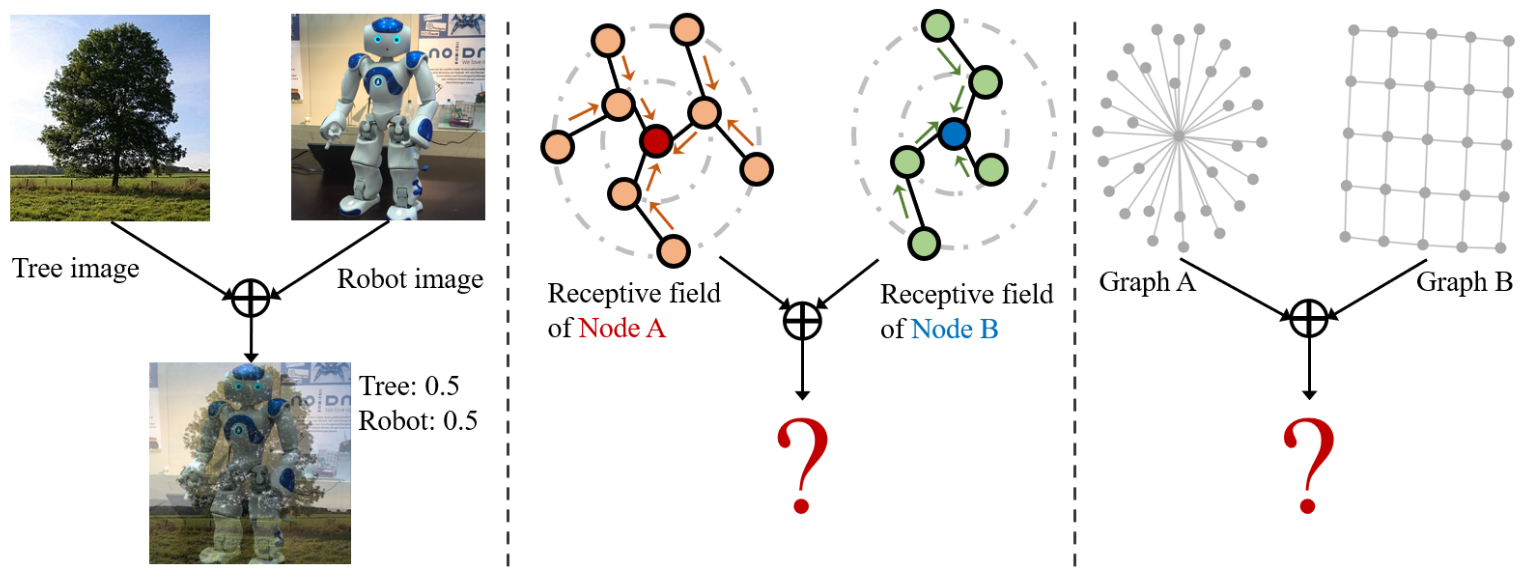 (左)对于图像分类,现有的 Mixup 通过对图像像素和标签进行插值来生成合成图像。 (中)对于节点分类,要混合一对节点 A(红色)和 B(蓝色),我们需要混合它们的感受野子图。 (右)对于图分类,要混合一对图的节点和图拓扑。
(左)对于图像分类,现有的 Mixup 通过对图像像素和标签进行插值来生成合成图像。 (中)对于节点分类,要混合一对节点 A(红色)和 B(蓝色),我们需要混合它们的感受野子图。 (右)对于图分类,要混合一对图的节点和图拓扑。
方法
Mixup 首次在 [1710.09412] mixup: Beyond Empirical Risk Minimization (arxiv.org) 中提出用于图像分类。考虑一对样本 (x_i , y_i) 和 (x_j , y_j),其中 x 表示输入特征,y 表示独热类标签。 Mixup 产生的合成样本如下:
其中 λ ∈ [0, 1]。通过这种方式,Mixup 通过结合先验知识来扩展训练分布,即特征插值应导致相关标签的插值。Mixup 的实现随机选取一张图像,然后将其与从同一小批量中提取的另一张图像配对。
对于图学习中的两个基本任务:节点和图分类中通常通过 GNN 的消息传播机制得到节点的特征表示:
其中W(l)表示第l层的可训练权重,AGGREGATE 是特定 GNN 模型定义的聚合函数。\mathbf{h}_i^{(0)}=x_i 在输入层成立。对于节点分类,GNN 通过堆叠 L 层并最小化最终层预测的分类损失(如交叉熵)来学习高级语义表示。对于图分类,GNN 通过 READOUT 函数将节点的表示总结为单个图嵌入:
其中 READOUT 可以是简单的排列不变函数(例如求和)或更复杂的图池化函数。由于图数据的不规则性和连通性,设计用于图学习的 Mixup 具有挑战性。
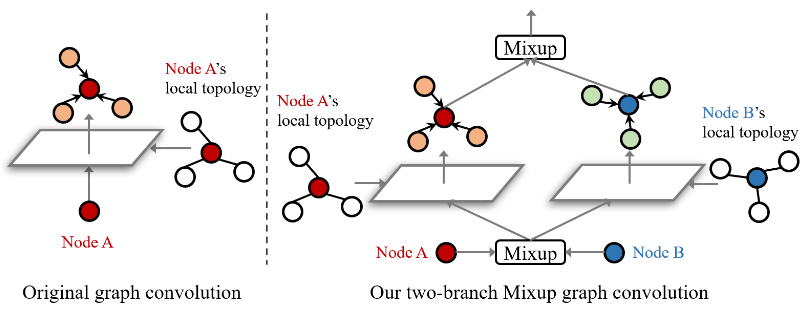
GNN 层通过聚合自身及其邻居的表示来更新节点 i 的表示。通过堆叠 L 层,GNN 根据节点 i 的 L 跳邻域对节点 i 进行最终层预测,这称为节点 i 的感受野。所以为了对配对节点 i 和 j 进行插值,我们需要混合它们的感受野子图。其中在输入层之前混合节点 i 和 j 的节点属性:
然后在每一层分别根据节点 i 和 j 的拓扑进行图卷积:
并在下一层之前将两个拓扑的聚合特征混合在一起:
其中 \tilde{\mathbf{h}}^{(0)}_{ij}=\tilde{x}_{ij}。
简而言之,双分支混合图卷积对于要混合的一对节点(红色和蓝色),首先混合它们的属性。然后在每一层,分别在与成对节点(红色和蓝色)的图拓扑相对应的两个分支中进行图卷积,并在下一层之前混合来自两个分支的聚合表示。
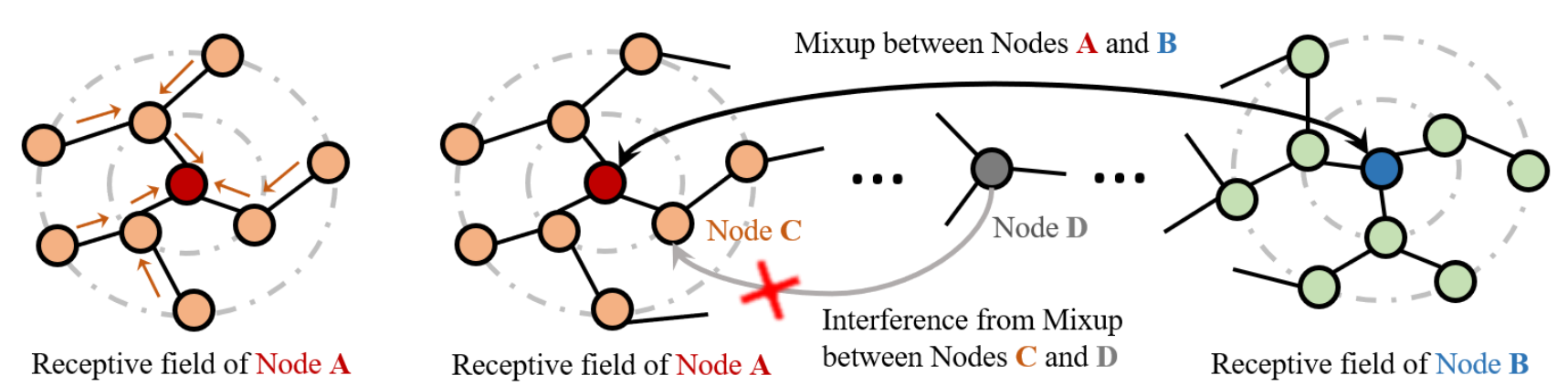
GNN 模型通过聚合节点 A 感受野内的节点(橙色)来预测节点 A(红色)的类别。 对于混合节点 A(红色)和 B(蓝色),我们应该混合 A 和 B 感受野内的特征。但是,如果我们同时对节点 C(橙色)和节点 D(灰色)进行 Mixup,则节点 A 和 B 的混合输入特征会受到节点 D 通过节点 C 的干扰的干扰,应该将其阻止。
为了解决上述问题,采用两阶段 Mixup 方法
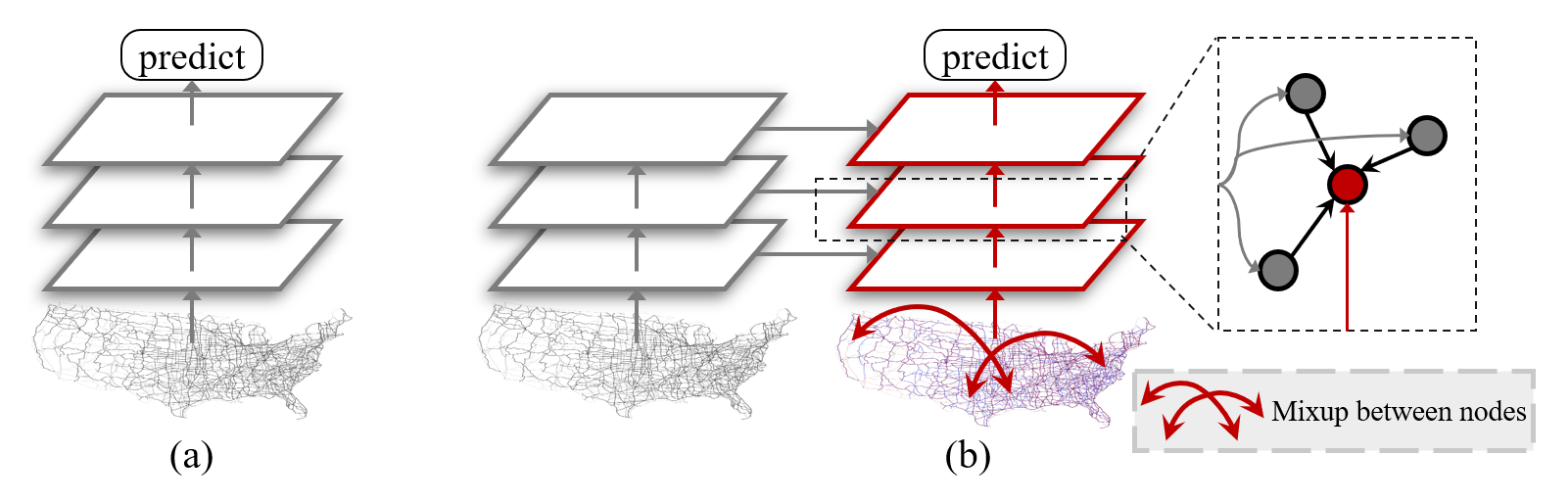
(a) 现有的 GNN 同时对小批量图中的所有节点进行分类。 (b) 我们提出了两阶段 Mixup 方法来解决不同节点对上的 Mixup 之间的冲突。在第一阶段,我们像在没有 Mixup 的现有 GNN 中一样执行前馈。然后在第二阶段,我们随机配对小批量图中的节点并混合它们的输入属性。接下来,我们对每一层的配对节点执行双分支混合图卷积,其中我们使用从第一阶段获得的每个节点的邻居表示。这确保了 Mixup 之后每个节点的表示不会干扰其他节点的“消息传递”。
在第二阶段的每一层,我们使用从第一阶段获得的没有混合的邻居表示来进行图卷积。这样,Mixup后每个节点的表示就不会干扰其他节点的“消息传递”。通过我们的两阶段框架,我们有效地防止输入特征受到感受野之外的节点的干扰。我们使用超参数 α 从分布 \mathrm{Beta}(α, α) 中采样混合权重 λ。
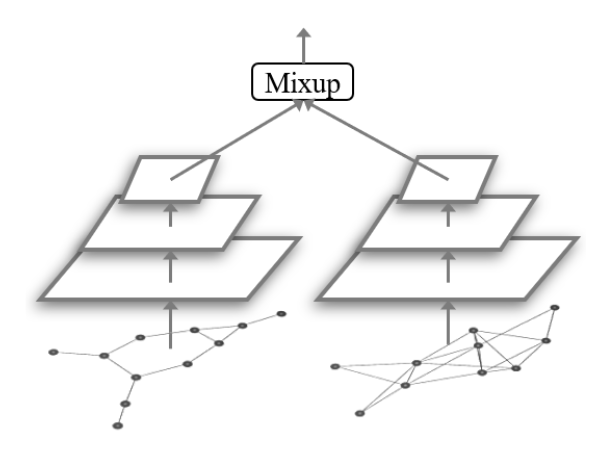
图神经网络利用 READOUT 函数将节点级嵌入总结为图嵌入。 GNN 将复杂且不规则的图结构嵌入到固定维度的嵌入向量中。我们在嵌入空间中进行图分类的 Mixup。具体来说,给定图 G1 和 G2 分别具有嵌入 \mathbf{h}_{G_1}、\mathbf{h}_{G_1} 和标签 \mathbf{y}_{G_1}、\mathbf{y}_{G_2},我们将它们混合为:
最后,插值图级嵌入 \tilde{\mathbf{h}}_{G_1G_2} 将传递到多层感知,然后是 softmax 层,以生成目标类的预测分布。