
项目地址:https://github.com/divelab/GOOD/.
这项工作中的目标是专门针对图形开发 OOD 基准(称为 GOOD)。作者明确区分协变量偏移和概念偏移,并设计准确反映不同转变的数据分割。同时考虑图和节点预测任务,因为两者设计偏移之间存在关键差异。总体而言,GOOD 包含 11 个数据集和 17 个域选择。当与协变量、概念和无偏移相结合时,可以获得 51 种不同的分割。同时还提供了 10 种常用基准方法(ERM、IRM、VREx、GroupDRO、Coral、DANN、Mixup、DIR、EERM、SRGNN)的性能结果,这样共有 510 种数据集-模型组合。
提出的 benchmark 中包含的数据集信息如下图。对于协变量偏移,训练和测试示例来自不同的领域。对于概念偏移,从具有不同标签的同一域中选择示例来显示不同的域输出相关性。

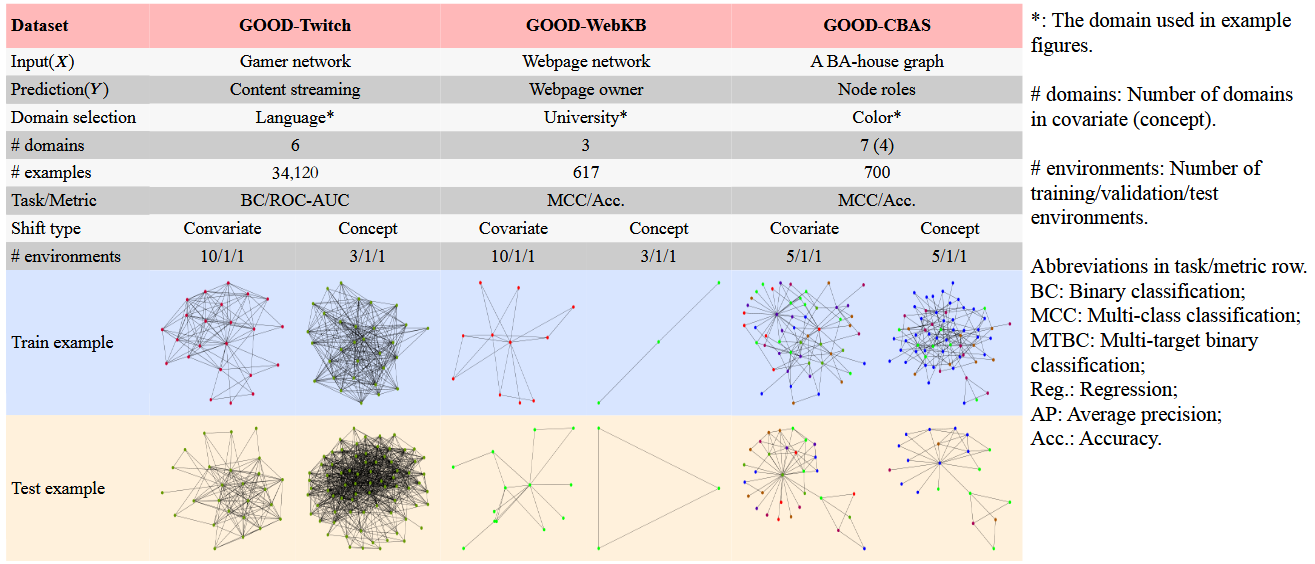 数据集
数据集
图预测任务
GOOD-HIV:输入是分子图,其中节点是原子,边是化学键。任务是预测该分子是否可以抑制HIV复制。
GOOD-PCBA:包括 128 个生物测定,形成 128 个二元分类任务。
GOOD-ZINC:输入是最多 38 个重原子的分子图,任务是预测分子的受限溶解度。
GOOD-SST2:自然语言情感分析数据集。每个句子都被转换为语法树图,其中每个节点代表一个单词,并以相应的单词嵌入作为节点特征。该数据集形成二元分类任务来预测句子的情感极性。
GOOD-CMNIST:是一个专为节点特征偏移而设计的半人工数据集。它包含使用超像素技术从 MNIST 数据库转换而来的手写数字图。
GOOD-Motif:是一个合成数据集,专为结构偏移而设计。GOOD-CMNIST 和 GOOD-Motif 组成了针对特征/结构偏移的 OOD 算法检查。数据集中的每个图都是通过连接基本图和主题生成的,并且标签仅由主题确定。
节点预测任务
GOOD-Cora:输入是一个小规模的引文网络图,其中节点代表科学出版物,边是引文链接。该任务是对出版物类型进行 70 类分类。
GOOD-Arxiv:输入是一个有向图,表示计算机科学 (CS) arXiv 论文之间的引用网络。图中的节点代表 arXiv 论文,有向边代表引用。任务是预测 arXiv CS 论文的主题领域,形成 40 类分类问题。
GOOD-Twitch:是一个游戏玩家网络数据集。节点代表游戏玩家,以游戏为节点特征,边代表游戏玩家之间的友谊联系。二元分类任务是预测用户是否流式传输成人内容。
GOOD-WebKB:是一个大学网页网络数据集。网络中的节点代表一个网页,网页中出现的单词作为节点特征,边是网页之间的超链接。它的 5 类预测任务是预测网页的类别。
GOOD-CBAS:输入是通过将 80 个类似房屋的主题附加到 300 个节点的 Barabási-Albert 基本图而创建的图,任务是预测节点的角色,包括类似房屋的主题的顶部/中间/底部节点或基础图中的节点,形成 4 类分类任务。
Benchmark 设计
当训练和测试样本被假设为独立同分布时,通常使用随机分割将数据集分割为训练集和测试集。OOD 问题中的分割则应该仔细设计,以便准确评估算法的泛化能力。GOOD 中,文章同时考虑协变量偏移和概念偏移(详见【知识】领域泛化及其理论基础 - Dymay)。
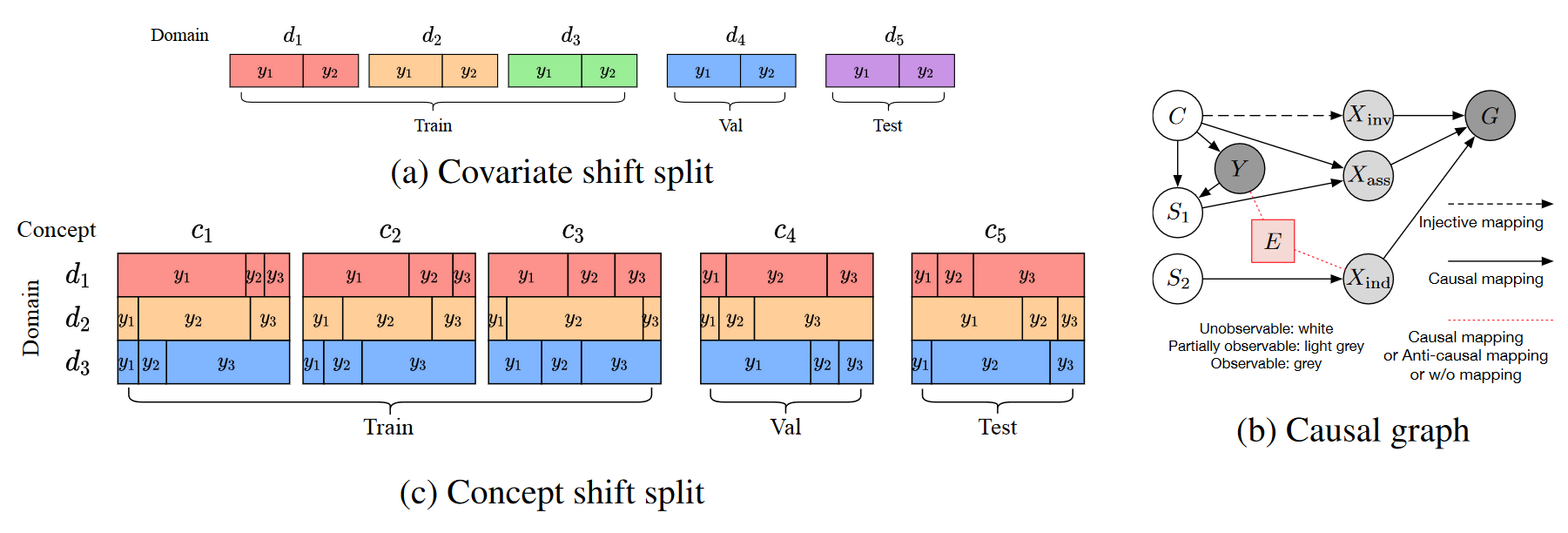 (a) 协变量偏移分割的图示。五个域用不同的颜色表示,其中每个域包含相同分布的输出。我们根据域 d_i 对数据集进行排序,然后将它们分组为训练/验证/测试集。 (c) 概念偏移分割的说明。每个概念都包含所有三个域,并且每个域都与概念中的特定输出存在虚假相关性。例如,在概念 c_1 中,红色域与 y_1 高度相关,但该域对应于概念 c_4 中的 y_2。请注意,训练中概念的分布是相似的。 (b) 用于数据集生成和观察的因果图的图示。 (左)C、S1、S2 位于潜在空间,不可观测。 (中)X_\mathrm{inv}、X_\mathrm{ass} 和 X_\mathrm{ind} 是可以部分观察和手动选择的输入特征,例如主题形状或分子支架。 (右)G 是图数据输入,包括节点特征和邻接矩阵。 E ∈ \mathcal{E} 是环境变量,可以根据不同类型的数据集和班次来确定或由X_\mathrm{inv} 和 Y 确定。
(a) 协变量偏移分割的图示。五个域用不同的颜色表示,其中每个域包含相同分布的输出。我们根据域 d_i 对数据集进行排序,然后将它们分组为训练/验证/测试集。 (c) 概念偏移分割的说明。每个概念都包含所有三个域,并且每个域都与概念中的特定输出存在虚假相关性。例如,在概念 c_1 中,红色域与 y_1 高度相关,但该域对应于概念 c_4 中的 y_2。请注意,训练中概念的分布是相似的。 (b) 用于数据集生成和观察的因果图的图示。 (左)C、S1、S2 位于潜在空间,不可观测。 (中)X_\mathrm{inv}、X_\mathrm{ass} 和 X_\mathrm{ind} 是可以部分观察和手动选择的输入特征,例如主题形状或分子支架。 (右)G 是图数据输入,包括节点特征和邻接矩阵。 E ∈ \mathcal{E} 是环境变量,可以根据不同类型的数据集和班次来确定或由X_\mathrm{inv} 和 Y 确定。